
Remember the glory days? When you could throw your entire website into Claude and expect it to parse everything? Yeah, me neither.
Context windows are the frustrating reality for any LLM user that’s really digging into website research. No matter the size, it’s never enough for the job at hand. The days of dumping your entire knowledge base into a prompt are long gone, if they existed at all.
Let me share a little secret. MCP crawler context window can make these troubles evaporate in an instant. It’s all about the Boolean search renaissance you didn’t even know you needed. Simply hand your LLM an advanced search interface of your web content, and let it rock and roll.
Context Window Blues
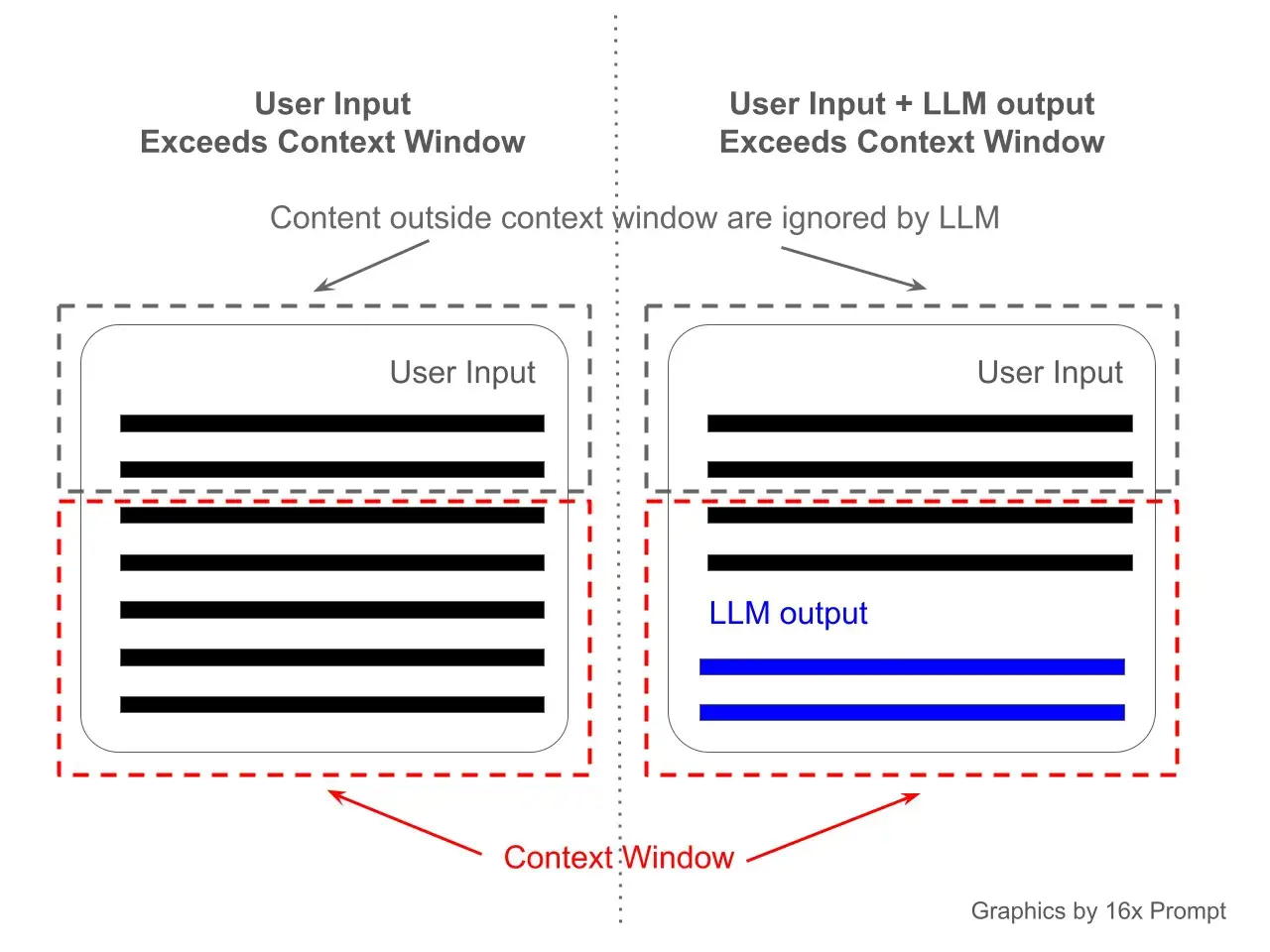
Claude’s context window is impressive, but it’s still a window. It’s certainly not a door. When you need to reference an entire website’s worth of content, even the largest context windows will eventually give way. You’re left with a miserable game of webpage Tetris, trying to cram just enough copy in without hitting the token ceiling.
This limitation becomes geometrically worse when dealing with technical documentation, web knowledge bases, or any substantial web archive. The traditional solutions fall short:
* **Drag/Drop/Copy/Paste**: fine for some use cases, but tedious
* **Summarization**: critical detail loss through compression
MCP: the New Hotness
Model Context Protocol (MCP) is new and generating buzz. But don’t let that fool you. It’s a shipped technology that Anthropic, Microsoft, and OpenAI have all endorsed, and is fast becoming a standard.
MCP acts as an API connection between language models and external data sources, in this case, your crawl archives.
It’s the missing layer that lets Claude reach beyond its context window into bits and pieces of web content on request. No need to cram it into prompts.
mcp-server-webcrawl has one role: it creates a search interface between your web crawls and the LLM.
Available via pip, and configurable with a few lines of JSON:
“`
pip install mcp-server-webcrawl
“`
The Python implementation abstracts away the complexity of multiple crawler formats. Whether you’re using command line options like wget, WARC, Katana, or a GUI crawler like InterroBot or SiteOne, the server handles the translation to a common search interface.
Search Like it’s 1999
Let’s be real, Boolean search has something of a 1990s academic vibe to it. It’s an approach many were forced to learn before the natural language search revolution.
It wasn’t for lack of utility that Boolean search was left by the wayside. Alas, it was just too difficult for regular people that didn’t live and breathe data.
With mcp-server-webcrawl, you’re giving Claude access to the cold, hard algebra of Boolean search. Not the fuzzy match commonly implemented by search engines today, but actual, precise results:
* keyword
* “privacy policy”
* boundar*
* privacy AND policy
* privacy OR policy
* policy NOT privacy
* id: 12345
* url: example.com/*
* type: html
* status: 200
* status: >=400 AND url: /blog/
* content: sale AND url: /products/
* headers: text/xml
* (login OR signin) AND form
* type: html AND status: 500
This way, mcp-server-webcrawl can reduce the noise (and subsequent token usage).
By taking advantage of precision search, with the option to only retrieve the fields you want (or the LLM deems necessary), you gain further savings of context.
It slices, it dices, it carves up information into easily digestible chunks that won’t break the token bank, and yet, it delivers exactly what you asked for.










